- Start memoQ.
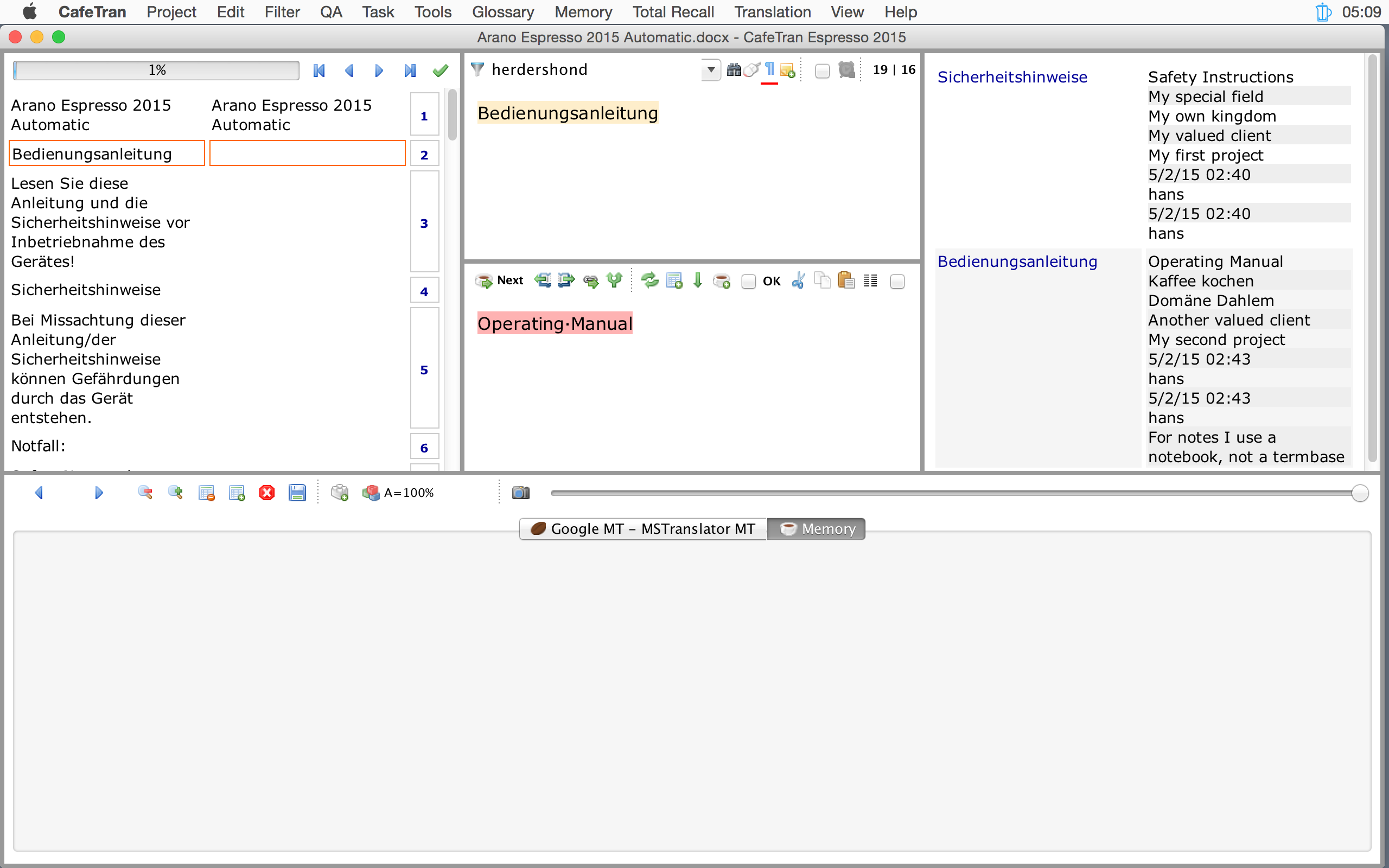
- On the Term Bases tab, click on the Export button.
- Select the Tab delimiter.
- Check the fields that you want to export (Domain, Client see below for the available fields)
- Set the path for the export file (e.g. c:\Users\Igor\Documents\mQ-termbase.txt)
- Click on the Export button at the bottom of the dialogue box.
Modifying the exported tab-delimited file
You can open the exported memoQ termbase in any Unicode-compatible text editor or in a spreadsheet software (e.g. to change column names, delete or rearrange columns etc.):

Things to consider
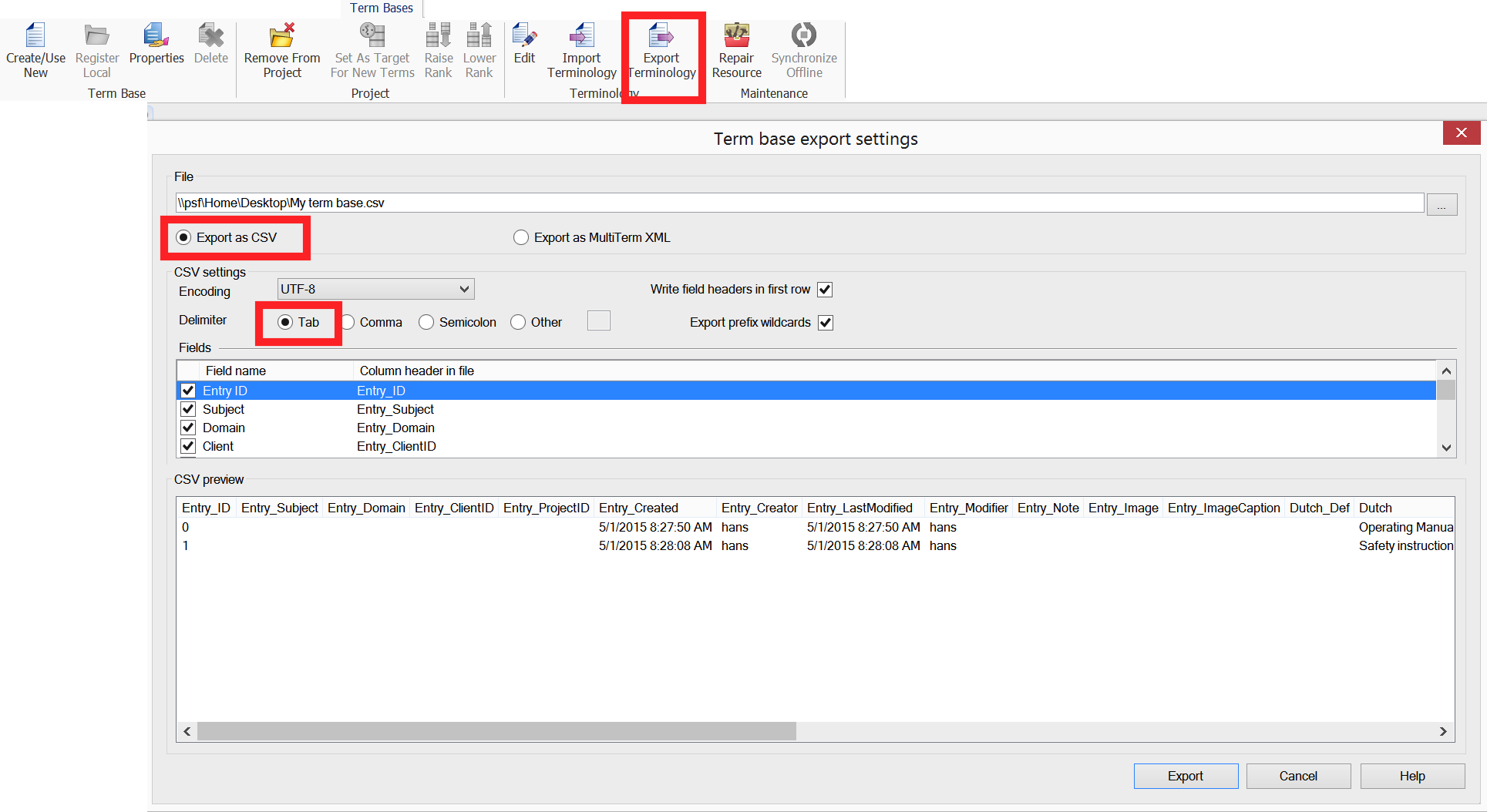
- Make sure that all column names begin with a ‘#’, since CafeTran will use this hash character to identify field names.
- In your spreadsheet software, move the columns containing the source terms and the target terms to the first and second column respectively.
- Best, change the names of the source and target columns to the respective language codes. E.g. #de-DE for German and #en-GB for English.
- You probably want to delete the Entry_ID column, since CafeTran has no use for it.
- You probably want to delete the Term_Info column, since CafeTran has no use for it.
- You can leave any pipes (vertical bars, |) in the source terms, since CafeTran can use them too, see below for Stemming.
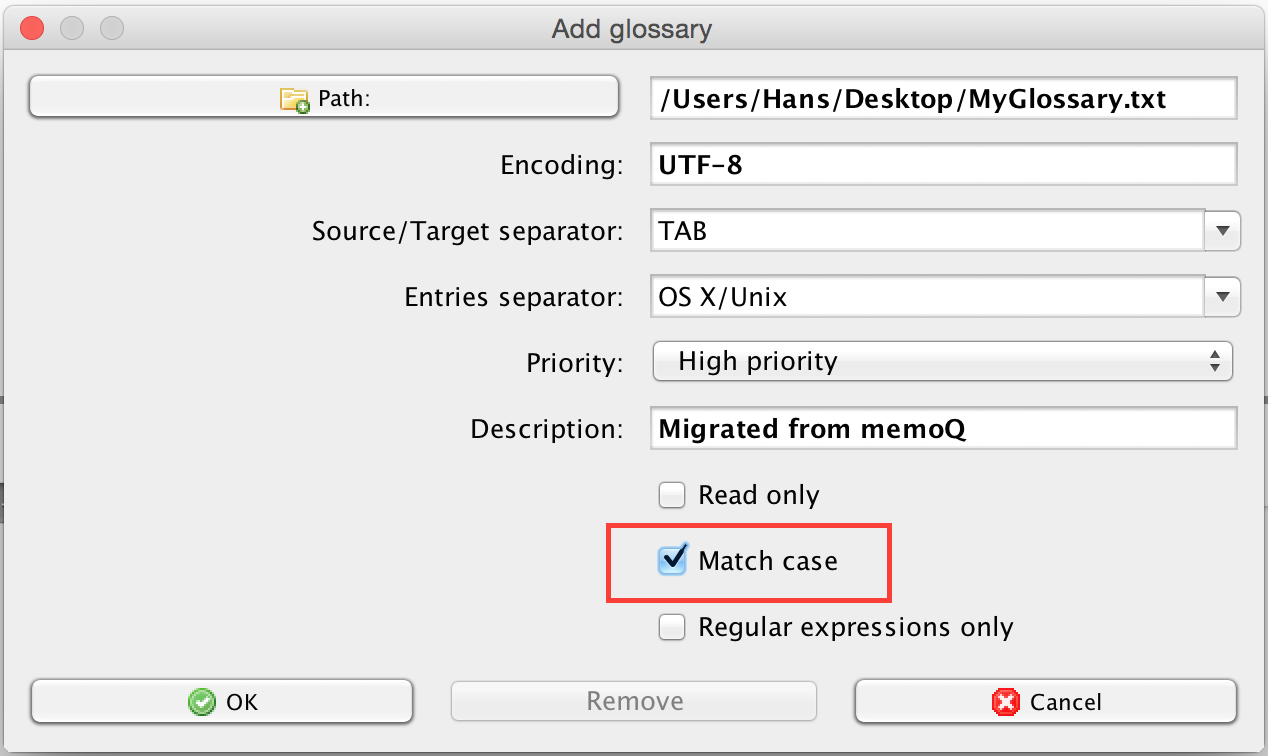
- Note that CafeTran doesn't specify case sensitivity on a glossary entry level (except in entries that are regular expressions). Instead it specifies case sensitivity on a glossary level (see: Adding an existing glossary):
Available fields
memoQ termbases can have the following fields, which will return as columns in the export file:
Matching: Fuzzy, 50% prefix, Exact, Custom (can contain pipes and asterisks)
Case sensitivity: Yes, No (not relevant for CafeTran)
Part of speech: noun, adjective, adverb, verb or other parts of speech
Gender: masculine, feminine, or neutral
Number: singular or plural.
Other:
- ID
- Note
- Project
- Domain
- Created by
- Modified by
- Client
- Subject
- Created at
- Modified at
- Forbidden term
- Example
etc.
Stemming
Example: enter piękn|y (beautiful) as a source term and pięknego, pięknych etc. will also be recognised. See here, here and here.
More images
The exported memoQ termbase loaded in a spreadsheet program, field names already adjusted for CafeTran:

Superfluous columns removed and source and target columns rearranged:

The spreadsheet content copied to TextWrangler via the clipboard. Note the UTF-8 encoding and the Unix linefeeds:
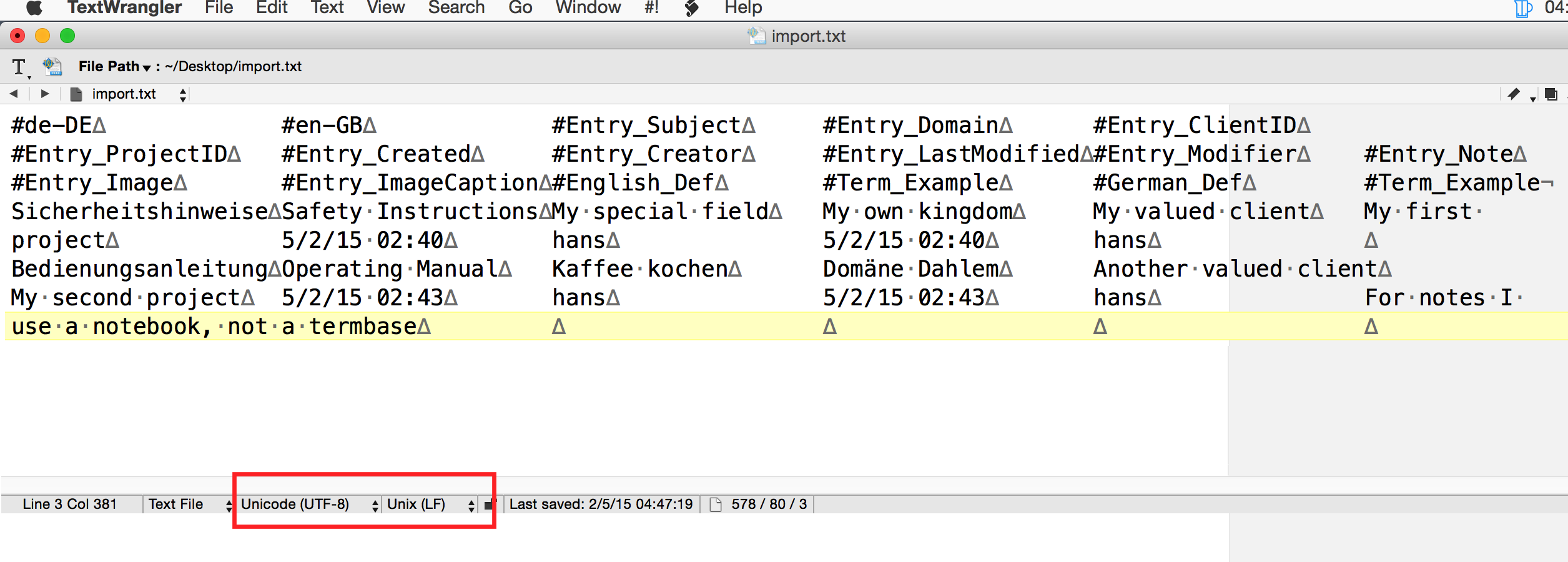
Et voila, the result in CafeTran: