TMX Memory
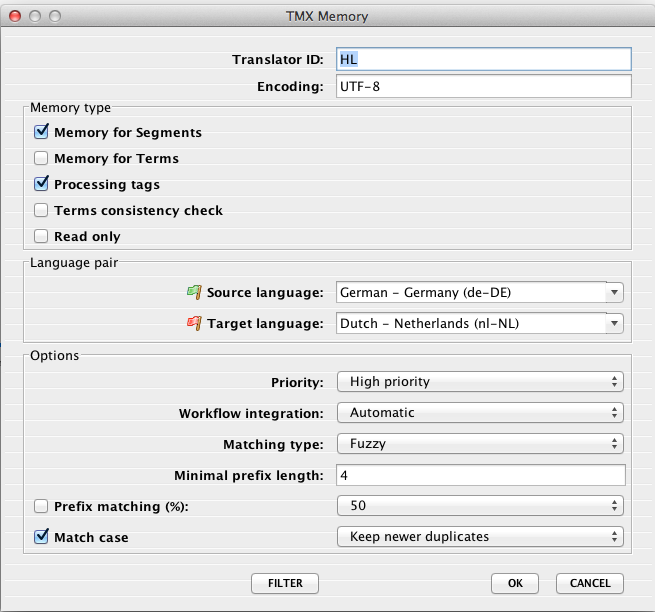
Translator ID field
- Insert or adjust your Translator ID.
Encoding field
- Make any necessary changes to the encoding type of the TMX file – this is only necessary when ??
Memory type group
- Leave the Memory for Segments box checked.
- Consider to check the Memory for Terms box when you want to use the TM for ??auto-assembling.
- Leave the Processing tags box checked to let CafeTran store positions of inline tags in the TM.
- Check the Terms consistency check box if you want to check the consistency of target terms used in your translation.
- Check the Read only box if you load a large TMX file and/or don't want to make any changes to the TM.
Language pair group
- Select your Source language.
- Select your Target language.
Options group
- Select the Priority for your TM: High, Medium or Low.
- Choose the Workflow integration mode: Automatic, Pretranslation or Manual.
- Choose the Matching type: Fuzzy and subsegment, Fuzzy, Detailed matching, Prefix matching or Custom prefixes.
- Select the Minimal prefix length: Set the minimal allowed length of prefixes.
- Check the Prefix matching (%) box when ??
- Leave the Match case box checked if you want CafeTran to differentiate between identical TUs that only differ in case (uppercase / lowercase). Note: The same can be done for Glossaries, at Edit > Options > Memory > Auto-assembling > Match case
- Select Keep newer duplicates when you want CafeTran to overwrite old TUs in the TU when you add a new translation for them.
- Select Keep older duplicates when you want to ignore new identical source segments which are already present in the memory.
- Select Keep all duplicates when you want to keep both newer and older identical source segments in the memory.